What is Exfil
Exfil is an intelligent document processing and data extraction solution that turns your documents into data. Using machine learning, the solution automates the extraction of data from any document type and supports all major file types (PDF, Word, Excel, Tiff, PNG, JPEG and more).
With Exfil you can
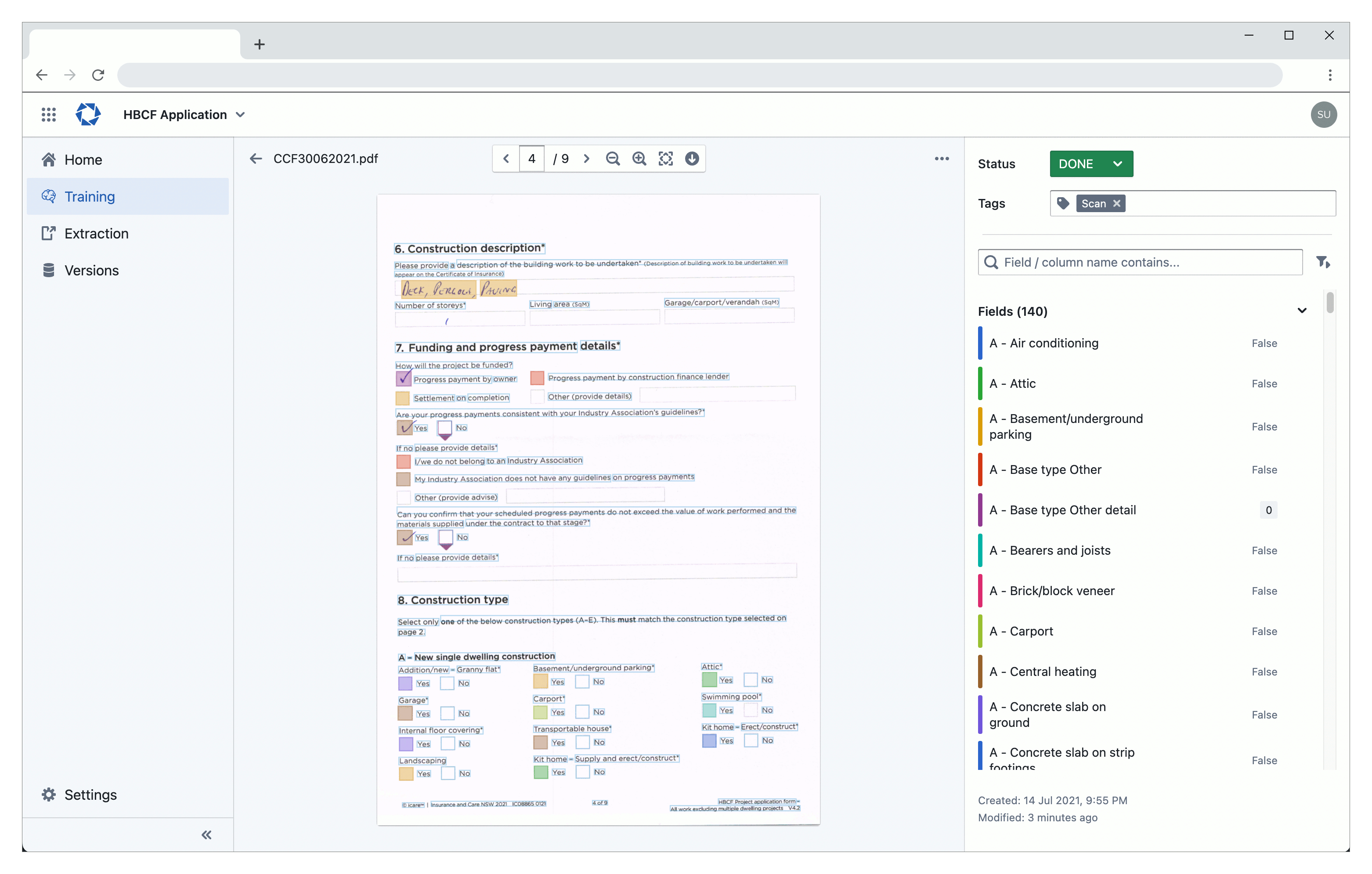
Extract structured and semi-structured data - Extract content from various structured or semi-structured documents using the latest in natural language, machine learning, and optical character recognition. Exfil does not reply on pre-built templates or models, so you can define any field configuration and support any type of document.
Continuous improvement - Extraction accuracy improves over time. Every mistake is used to fine-tune the underlying model, improving accuracy and performance.
Deploy in days - Most projects are trained in hours and deployed in days. The solution can either be integrated into your existing platform or used as a stand-alone solution.
Export to main output types - Extracted data can be accessed via a secure REST API, inserted into your SQL database, or received via an automated reply-to email. Data can also be saved as JSON, XML, or Microsoft Excel spreadsheet.
Model roll back and versioning - Train multiple models and deploy with confidence. Test a model before making it active or roll back to a previous model if there are any issues.